AI🤖さん、こんにちは。

Python, Chainer, Dockerを使って、将棋AIのサンプルを動かしてみました。
Chainerとは、日本で生まれたディープラーニング向けのフレームワークです。Preferred Network社が開発しています。
今回、参考にした本は「将棋AIで学ぶディープラーニング」(マイナビ出版)になります。リンクは最後に貼りました。
インストール環境になります。
| CPU | x64命令互換64ビットCPU |
| GPU | NVIDIA Geforce GTX 1060 |
| OS | Host: CentOS 7, Guest: Ubuntu16, 将棋所: Windows 10 Pro |
ソフトウェアのバージョンです。
| ソフトウェア名 | バージョン |
| Anaconda | Anaconda3.8.3.0(64bit) |
| Python | 3.8.3 |
| Cupy | 7.7.0 |
| Chainer | 7.7.0 |
| Docker | 19.03.12 |
今回は方策ネットワーク(policy network)というニューラルネットワークを使って、ディープラーニングを行いました。
ポイントはDocker上にあるゲストのUbuntuからホストのGPUに接続する所でした。以下はゲストのUbuntuでホストのGPUの動作を確認した所になります。GPUを使うと学習時間が短縮できます。
$ nvidia-smi
Mon Aug 10 01:39:27 2020
+-----------------------------------------------------------------------------+
| NVIDIA-SMI 450.57 Driver Version: 450.57 CUDA Version: 11.0 |
|-------------------------------+----------------------+----------------------+
| GPU Name Persistence-M| Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap| Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|===============================+======================+======================|
| 0 GeForce GTX 106... Off | 00000000:01:00.0 On | N/A |
| 0% 52C P8 12W / 120W | 505MiB / 3016MiB | 0% Default |
| | | N/A |
+-------------------------------+----------------------+----------------------+
+-----------------------------------------------------------------------------+
| Processes: |
| GPU GI CI PID Type Process name GPU Memory |
| ID ID Usage |
|=============================================================================|
| 0 N/A N/A 1562 G /usr/bin/X 227MiB |
| 0 N/A N/A 2155 G /usr/bin/gnome-shell 87MiB |
| 0 N/A N/A 2924 G ...AAAAAAAAA= --shared-files 184MiB |
+-----------------------------------------------------------------------------+
GPUが使えることを確認後、実際にChainerを使って、棋譜を学習させました。最初に訓練データの棋譜を1000件と、テストデータの棋譜を100件で作成した学習データです。
2020/08/11 12:35:33 INFO read kifu start
2020/08/11 12:35:34 INFO load train pickle
2020/08/11 12:35:34 INFO load test pickle
2020/08/11 12:35:34 INFO read kifu end
2020/08/11 12:35:34 INFO train position num = 139865
2020/08/11 12:35:34 INFO test position num = 14217
2020/08/11 12:35:34 INFO start training
2020/08/11 12:35:38 INFO epoch = 1, iteration = 100, loss = 7.650593, accuracy = 0.015625
2020/08/11 12:35:41 INFO epoch = 1, iteration = 200, loss = 7.2174034, accuracy = 0.01171875
2020/08/11 12:35:44 INFO epoch = 1, iteration = 300, loss = 6.744217, accuracy = 0.001953125
2020/08/11 12:35:47 INFO epoch = 1, iteration = 400, loss = 6.6463594, accuracy = 0.005859375
2020/08/11 12:35:50 INFO epoch = 1, iteration = 500, loss = 6.5667987, accuracy = 0.025390625
2020/08/11 12:35:53 INFO epoch = 1, iteration = 600, loss = 6.5046926, accuracy = 0.0078125
2020/08/11 12:35:56 INFO epoch = 1, iteration = 700, loss = 6.4815917, accuracy = 0.013671875
2020/08/11 12:35:59 INFO epoch = 1, iteration = 800, loss = 6.450376, accuracy = 0.04296875
2020/08/11 12:36:02 INFO epoch = 1, iteration = 900, loss = 6.433092, accuracy = 0.01171875
:
結果をグラフにしました。lossは損失、accuracyはテストデータとの一致率を示します。lossが下降して、accuracyが上昇しています。
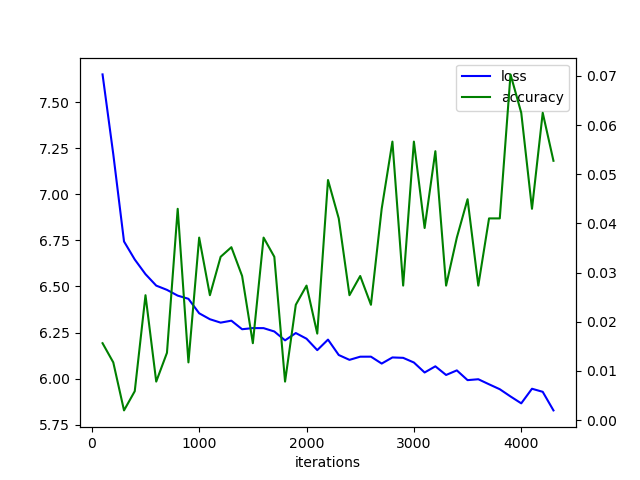
次に2016年の80,141件の棋譜データから訓練用データとテストデータを作成して、学習した結果です。
2020/08/11 12:44:43 INFO read kifu start
2020/08/11 12:45:17 INFO load train pickle
2020/08/11 12:45:19 INFO load test pickle
2020/08/11 12:45:19 INFO read kifu end
2020/08/11 12:45:19 INFO train position num = 3712656
2020/08/11 12:45:19 INFO test position num = 413188
2020/08/11 12:45:19 INFO start training
2020/08/11 12:45:27 INFO epoch = 1, iteration = 100, loss = 7.6596613, accuracy = 0.013671875
2020/08/11 12:45:30 INFO epoch = 1, iteration = 200, loss = 7.4310913, accuracy = 0.0078125
2020/08/11 12:45:33 INFO epoch = 1, iteration = 300, loss = 6.857481, accuracy = 0.0078125
2020/08/11 12:45:36 INFO epoch = 1, iteration = 400, loss = 6.6683636, accuracy = 0.013671875
2020/08/11 12:45:39 INFO epoch = 1, iteration = 500, loss = 6.6142497, accuracy = 0.009765625
2020/08/11 12:45:42 INFO epoch = 1, iteration = 600, loss = 6.5848265, accuracy = 0.029296875
2020/08/11 12:45:45 INFO epoch = 1, iteration = 700, loss = 6.5157375, accuracy = 0.017578125
2020/08/11 12:45:48 INFO epoch = 1, iteration = 800, loss = 6.528902, accuracy = 0.0234375
2020/08/11 12:45:51 INFO epoch = 1, iteration = 900, loss = 6.433339, accuracy = 0.013671875
:
同じようにグラフにしました。
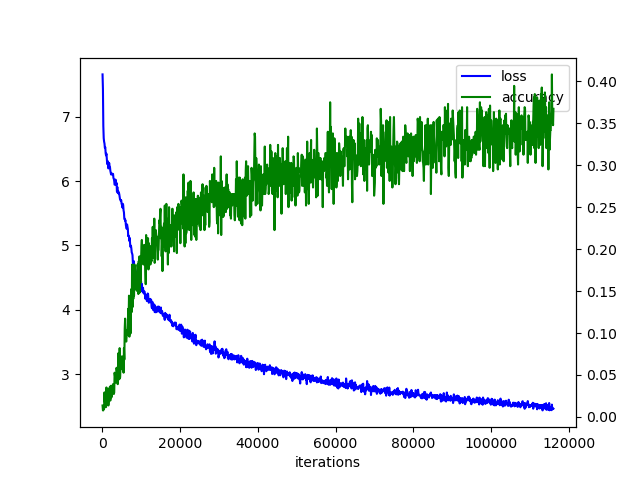
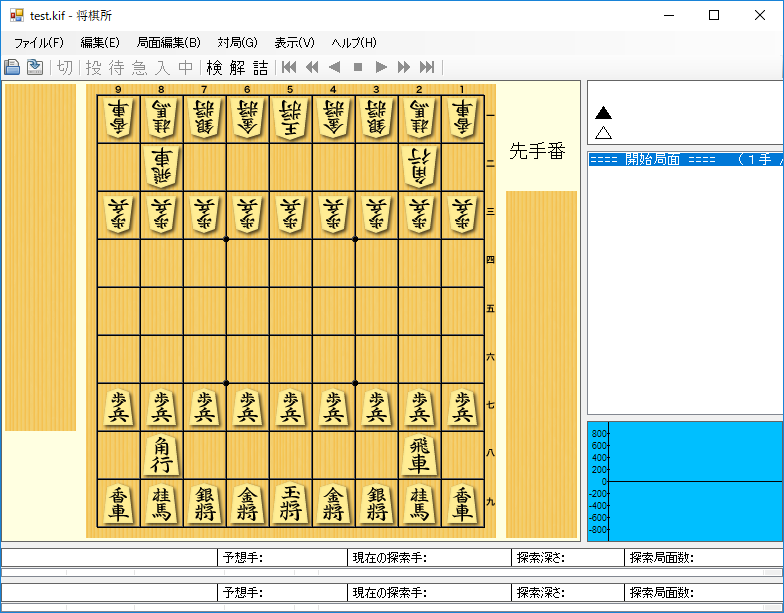
学習した方策ネットワークを将棋所のソフトに組み込みます。
今日はここまでとなります。今後は、方策ネットワーク、価値ネットワーク、モンテカルロ木探索などのディープラーニングを使って、どの方法が強いか試してみたいと思います。
ゆくゆくは、「ラジコン DE 自動運転」の制御に応用できれば良いなぁと思っています!

